The purpose of this project is to understand what, where and how each user is listening to the songs in the meta data generated base on the Million Song Dataset. The analytial goals is to find out what is making the free tier users switch to paid tier and why paid users are downgrading to free tier through their listening habits.
Project Datasets
Song Dataset
- Subset of the real data from Million Song Dataset
- Each file is in JSON format and contains metadata about a song and the artist of that song
Log Dataset
- Log files are in JSON format generated by this event simulator based on the songs in the dataset above
- These simulate activity logs from a music streaming app based on specified configurations
- The dataset are partitioned by year and month
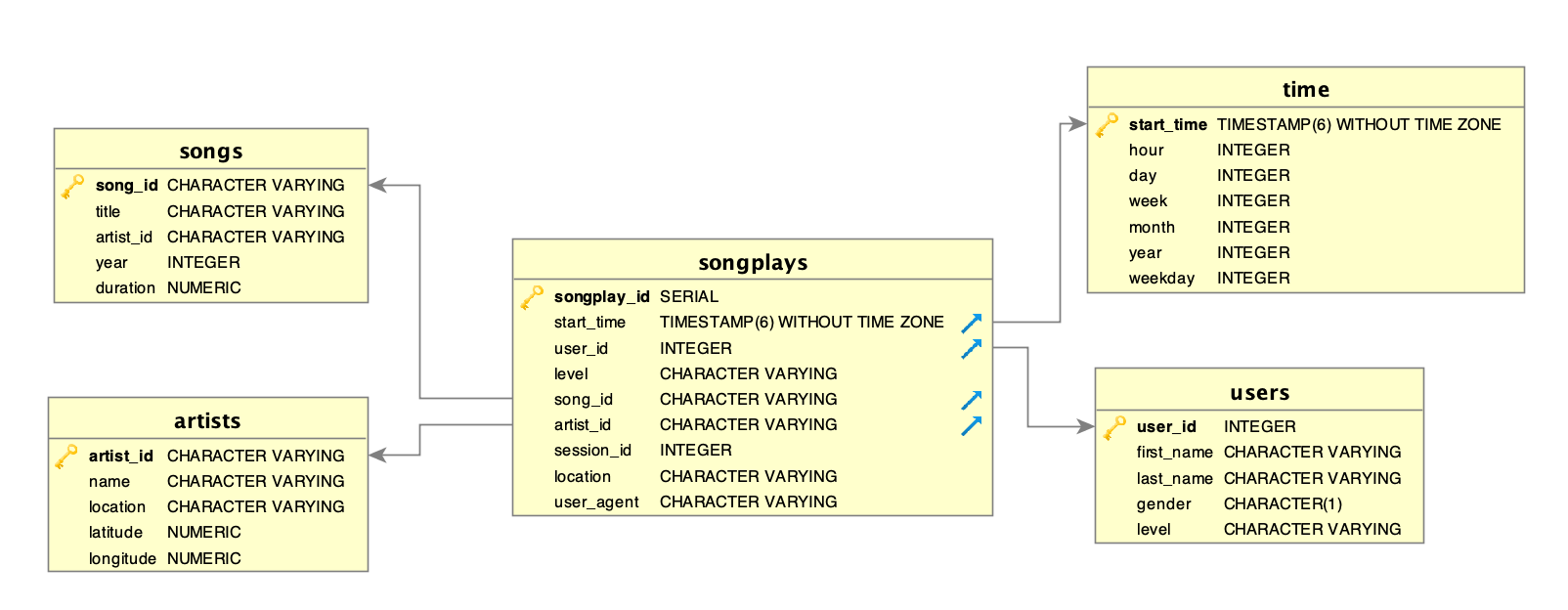
Database schema design
We have 1 fact table (songplays), and 4 dimension tables (users, songs, artists, time).
Data Modeling with PostgreSQL
- Used postgres to create database schema and perform data pipeline ETL
Data Warehouse (AWS Redshift, S3)
- Performs ETL loading data from S3 to Redshift
Data Lake (Spark, AWS Redshift, S3)
- Performs ETL loading data from S3 using Spark to Redshift
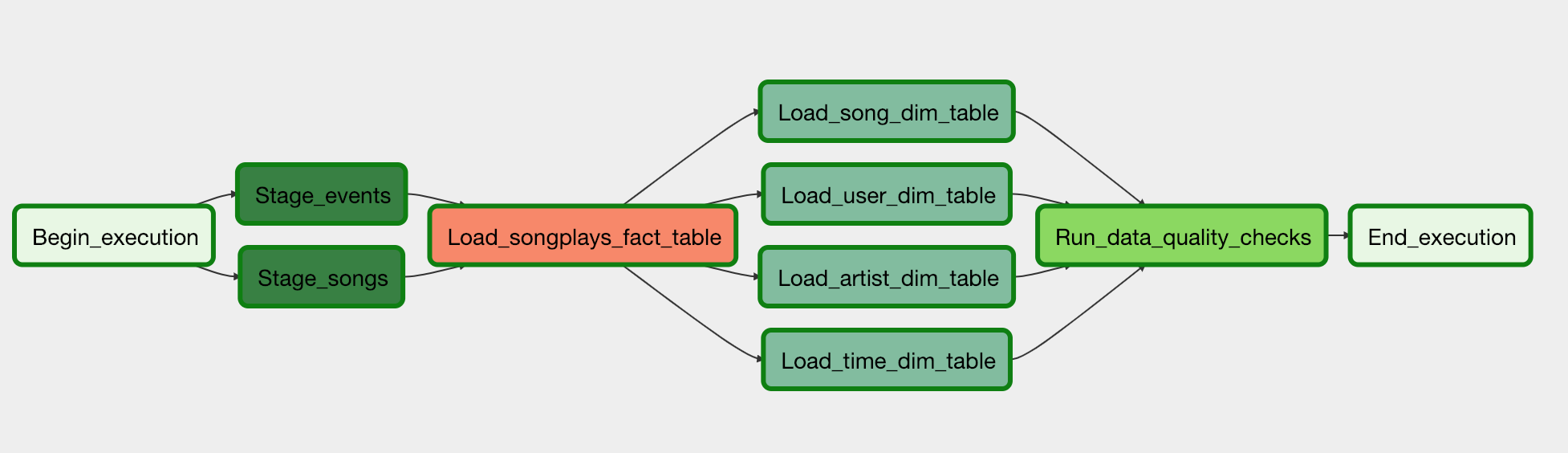
Data Pipeline with Airflow (AWS Redshift, S3)
- Using Apache Airflow to automate and monitor to data warehouse ETL pipelines
- Build a dynamic, reusable, and allow easy backfills ETL pipeline through data quality checks